0x00 背景
凭借乌云漏洞报告平台的公开案例数据,我们足以管中窥豹,跨站脚本漏洞(Cross-site Script)仍是不少企业在业务安全风险排查和修复过程中需要对抗的“大敌”。
XSS可以粗分为反射型XSS和存储型XSS,当然再往下细分还有DOM XSS, mXSS(突变XSS), UXSS(浏览器内的通用跨站脚本)。其中一部分解决方法较为简便,使用htmlspecialchars()对HTML特殊符号做转义过滤,经过转义的输入内容在输出时便无法再形成浏览器可以解析的HTML标签,也就不会形成XSS漏洞。
 (图:htmlspecialchars函数的转义规则)
(图:htmlspecialchars函数的转义规则)
但网站做大了,总有一些业务,比如邮件内容编辑、日志帖子类编辑发布等功能时,需要授权给用户自定义链接、改变字体颜色,插入视频图片,这时就不得不需要需要引入HTML富文本实现相应功能。之前提到,htmlspecialchars()这样把所有特殊符号做转义处理的过滤办法,这是就英雄无用武之地,因为HTML标签全部被过滤了,那之前提到的这些用户可以自定义功能又该如何实现?
一个问题总有它的解决办法,所以基于白/黑名单防御思想的富文本内容过滤器应运而生,并很快被应用到了对抗富文本存储型XSS的前沿。它的任务就是根据内置的正则表达式和一系列规则,自动分析过滤用户提交的内容,从中分离出合法和被允许的HTML,然后经过层层删除过滤和解析最终展示到网页前端用户界面来。这样既不影响网站的安全性,也不会妨碍到用户自定义富文本内容功能的实现。
道高一尺魔高一丈,经过一些前期的手工测试和侧面从乌云公开的漏洞报告中了解,大多数网站的富文本过滤器采用“黑名单”的设计思想。这也为我们使用模糊测试来自动化挖掘富文本存储型XSS提供了可能性。
 (图:某国内知名邮箱的富文本过滤器基于“黑名单”设计逻辑)
(图:某国内知名邮箱的富文本过滤器基于“黑名单”设计逻辑)
与此同时,本文的主角,“强制发掘漏洞的利器”-- 模糊测试(Fuzzing Test),相信各位一定不会陌生。无论是在二进制还是在WEB端的黑盒测试中都有它立功的身影,从客户端软件漏洞的挖掘到WEB端弱口令的爆破,本质上都可以认为是一种模糊测试。
结合富文本过滤器“黑名单”的实现逻辑,接下来,本文将主要探讨这类富文本存储型跨站脚本的模糊测试之道。将模糊测试这一强大的漏洞挖掘武器通过精细的打磨,挖掘出大量的潜在缺陷。
0x01 找准目标,事半功倍
要进行模糊测试,首先要找准目标。知道目标有哪些地方有富文本编辑器,又有哪些种类,进一步推测其是否基于“黑名单”思想,是否可以进行自动化的模糊测试。才可以让我们接下来要进行的模糊测试,发挥出事半功倍的效果
并不是所有允许用户提交自定义内容的地方,都允许用户自定义富文本,如果网站已经在后端对所有提交的内容做了htmlspecialchars()的过滤,就意味着所有提交的内容都会被转义,也就不存在模糊测试的必要了。比如:

乌云漏洞报告平台的评论回复区域,后端的实现逻辑就是不允许用户传入富文本内容,对所有用户输入的内容做了htmlspecialchars()的过滤。也就是说,如果你传入类似:
#!js
<script>alert(1);</script> => <script>alert(1);</script>
这时无论你使用何种高大上的XSS Vector,都无济于事,被转义以后的内容,无法对构成XSS跨站脚本。
富文本编辑器也分很多种,比如基于HTML标签形式的富文本编辑器(Ueditor、Fckeditor),自定义富文本标签形式(Markdown, UBB),在国内外各大网站都有使用。模糊测试万变不离其宗,你有了一把锋利的斧头,你无论用什么方式砍柴,本质相同。只是有时候是类似Ueditor的编辑器,在进行模糊测试的时候,可能会更加方便容易。
 (图:百度Ueditor)
(图:百度Ueditor)
0x02 模糊测试框架
就好像写字之前你必须有一只笔,砍柴前必须有一把斧子一样,在开始针对富文本过滤器展开模糊测试之前,你必须得有一个可以自动生成Payload的模糊测试框架。无论使用JavaScript、PHP、Python还是更加小众亦或是高级的语言,模糊测试框架的中心思想就是,通过拼接思想动态生成大量的供模糊测试使用的Payload。对网站富文本编辑器的模糊测试,稍不同于对浏览器XSS Filter或者是对DOM特性的模糊测试,不过我们还是可以参考一些已经在互联网上公开的XSS Filter Fuzzer的现成代码,加以修改,为我所用,这里就不再赘述。
所以,在开始更深一步的模糊测试方案设计之前,请选择自己得心应手的一种程序设计语言,参考现成的XSS Filter Fuzzer,编写出一个或简单或复杂的模糊测试框架。
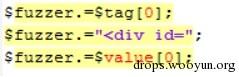 (图:基于拼接思想动态生成XSS Fuzzing Test Payload的框架代码)
(图:基于拼接思想动态生成XSS Fuzzing Test Payload的框架代码)
0x03 模糊测试模板
有了框架,就好比有了手枪,现在我们需要给它装上“子弹”-- 模糊测试模板。一个模糊测试模板的好坏,很大程度上决定了,之后我们是否能够高效的测试出富文本编辑器中潜在的缺陷,从而发掘出大量的存储型XSS构造姿势。而在设计自己的模糊测试模板时,主要需要考虑三点:边界、进制编码和字符集。
先来说说边界问题。以下面简单的HTML代码为例:
#!html
<span class=”yyy onmouseover=11111” style="width:expression(alert(9));"></span>
上述HTML标记语言文本传给后端富文本编辑器的时候,程序会如何过滤和解析?也许是这样的:首先匹配到<span,进入其属性值过滤的逻辑,首先是否含有高危的on开头的事件属性,发现存在onmouseover但被”,”包裹,作为class属性的属性值,所以并不存在危险,于是放行;接着分析style属性,其中有高危关键词”expression()”,又有括弧特殊符号,所以直接清除过滤。
上述过滤流程的实现,很大程度依赖于后端通过正则匹配进行的HTML标签中的边界分析。通过对“边界”的判定,类似class=”yyyy onmouserover=11111” 的属性及其值才会被放行,因为虽然onmouserover=11111虽然是高危的事件属性,但存在于=””中,没有独立成一个HTML属性,也就不存在风险。所以在上面的例子中,=””就是边界,<span中的尖括号也是边界,空格也可以说成一种边界。所以,形象一点说,一段HTML代码的边界位置很有可能是下面这样的:
#!html
[边界]<span[边界]class=[边界]yyy[边界]>[边界]</span[边界]>
所以如果是类似style="width:expr/*”*/esion(alert(9));"属性和属性值呢?程序又该如何确定边界?是style="a:expr/*”还是style="a:expr/*”*/ession(alert(9));"?
当后端富文本过滤程序遇到这样,略微复杂的选择题时,如果其后端规则设计的过于简单,就很有可能导致把不该过滤的过滤掉,而把非法的内容放行,从而我们可以构造出存储型XSS。打乱HTML边界,让后端富文本过滤器陷入选择窘境,这是我们设计模糊测试模板的原则之一。有哪些内容可能会导致富文本内容过滤器出现边界判断问题?
(1)特殊HTML符号,通过这类明显的符号,过滤器就可以到HTML标签及其属性,但这些符号错误的时候出现在了错误的地点,往往会酿成大祸,如:
=, ”, ’, :, ;, >, <, 空格, /,
(2)过滤器会过滤删除的内容,我们在边界填充下面这些元素,过滤器盲目删除,很有可能导致原本无害的属性值,挣脱牢笼,成为恶意的属性和属性值,如:
expression, alert, confirm, prompt, <script>,<iframe>
(3)不可打印字符,如:
\t、\r、\n、\0等不可打印字符
综上,现在我们已经可以用Fuzzer生成一个下面这样的Payload。幸运的话,或许已经可以绕过一些后端逻辑简单的富文本过滤器了,示例如下:
#!html
<<<span/class=/yyyy onmouseover=11111/style="a:exp/*”>*/resion(1);"></span>
当然,除了边界区分问题,富文本过滤器面对着另外两个劲敌,特殊的进制字符编码和千奇百怪的字符集。
我们先来说说字符编码,类似\x22,\40,"等一系列进制编码,直接当作文本内容传递给后端富文本过滤器,如果处理的办法?解密后过滤?直接输出?经验告诉我们,不少过滤器在处理类似特殊的进制编码时,往往会在进制编码的特殊HTML符号面前摔个人仰马翻。于是,像下面这样一段看似无害化的Payload,在富文本过滤器自作聪明的解密过后,变成了一段跨站脚本:
#!html
前:<span class=”yyy "onmouseover=alert(1);//”></span>
=>
后:<span class=”yyy“ onmouseover=alert(1);//”></span>
接下来,我们再来说说千奇百怪的字符集,不少富文本编辑器在处理类似“㊗”的unicode字符时,会将字符转化成<img>标签,所以在mramydnei报告的一个腾讯邮箱存储型XSS中,一段无害的Payload逆袭成了有害的跨站脚本:
#!html
前:<style x="㊗" y="Fuzzitup {}*{xss:expression(alert(document.domain))}">
=>
后:<style x="<IMG src=" https:="" res.mail.qq.com="" zh_cn="" htmledition="" images="" emoji32="" 3297.png"="">" y="Fuzzitup {}*{xss:expression(alert(document.domain))}"></style>
0x04 模糊测试实战
正所谓“磨刀不误砍柴工”,在进行模糊测试实战之前,我建议,对富文本过滤器的大改过滤规则和实现原理手动测试一番,了解哪些HTML标签允许被使用,有哪些关键词出现就会被删除,又有哪些Payload会触发网站存在的WAF,在之后的测试中,针对目标网站“个性化”的修改模糊测试模板。
讲到这里,相信你已经大概了解富文本跨站脚本模糊测试了,不过模糊测试的威力究竟如何呢?我们用实例来做论证:
网易有道云笔记存储型XSS [进制编码处理缺陷]
小米论坛存储型XSS [进制编码处理缺陷]
新浪邮箱存储型XSS [边界判定缺陷]
QQ邮箱存储型XSS [字符集处理缺陷]
QQ邮箱存储型 XSS [字符集处理缺陷]
0x05 写在最后
模糊测试只是自动化强制发现漏洞的一个重要手段,就像自动化漏洞扫描器一样。我们并不能完全依靠它,在测试过程中,对过滤器结果进行适时的分析,对模糊测试模板做出合理的改进,不仅能提高模糊测试的效率,还能够帮助我们挖掘到更多潜在的设计缺陷。毕竟,机器终究是“死板”的,而人是“灵活”的。
富文本跨站脚本测试之道,就是细致的模糊测试结果分析,加上对模糊测试模板的不断打磨,人与机器的结合,才会打造出一把真正的“神器”。
好文章,谢谢LZ分享
><span class=”yyy "onmouseover=console.log(1);//”></span><
测试 <span class=”yyy "onmouseover=console.log(1);//”></span>
好文!
好文章呀,楼主能不能把你fuzz过程总构造的那些payload姿势共享下呢
@r3d0x8 恩,确实有一些案例没有公开,我传了修改过的PDF版本到我的Github,补充了一下,希望对您有帮助,详情请见:https://github.com/martinzhou2015/Paper/。
xss fuzz似乎比较难fuzz,特别是存储型的,博主贴的几个漏洞还未公开,博主具体的fuzz过程能讲一下吗?
赞,构造payload一直是一块心病
一直想写个智能一点的fuzzer,但一直停留在想的阶段。看来洞主已经写出来了。
那么应该怎么办呢~
好文 晚上细读