0x00 背景介绍
全自动区分计算机和人类的图灵测试(英语:Completely Automated Public Turing test to tell Computers and Humans Apart,简称CAPTCHA),俗称验证码。CAPTCHA这个词最早是在2002年由卡内基梅隆大学的路易斯·冯·安、Manuel Blum、Nicholas J.Hopper以及IBM的John Langford所提出。CAPTCHA是一种区分用户是计算机或人类的公共全自动程序,在CAPTCHA测试中,作为服务器的计算机会自动生成一个问题让用户来解答。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。因为计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。
但是由于这个测试是由计算机来考人类,而不是像标准图灵测试中那样由人类来考计算机,所以更确切的讲CAPTCHA是一种反向图灵测试。[ 1 ]
0x01 常见验证码分类
文本验证码
文本验证码常以问答形式出现,如:给出问题要求用户答案,给出古诗上举要求用户写出下句等等。
因为所有的验证码问题和答案都要事先在数据库中存好,所以这类验证码数量有限。攻击者可以先将问题库中的所有问题先爬取下来并准备相应的答案库,破解时只需利用正则表达式将验证问题提取出来,然后从答案库中找到相应答案即可。
静态图验证码
静态图验证码是目前应用最广的一类验证码,这类验证码要求用户输入验证码图片上所显示的文字或数字,通过扭曲、变形、干扰等方法避免被光学字符识别(OCR, Optical Character Recognition)之类的电脑程序自动辨识出图片上的文字和数字。
但是由于许多验证码的设计者对验证码的意义理解的不到位,并且缺乏相关安全知识和经验,所以目前在用的很多验证码都是可以被轻松攻破的。
动态图验证码
动态图验证码看似更为复杂,但是实际上动态验证码提供了更大的信息冗余,冗余越大,提供的信息就越多,因此也越容易被识别。例如,在某一帧原本粘连严重的两字字符很能在另一帧中就比较好的分离开了。
语音验证码
许多开发者考虑到部分视觉障碍者,提供了语音验证码的功能,通过播放语音,让用户输入听到的内容来完成验证。图片验证码的识别主要是基于图像处理技术,而语音验证码的识别主要是基于音频处理,但是他们在识别的基本原理上是相同的。
短信验证码
随着手机的普及,现在很多网站、应用开始使用短信验证码。服务器将验证码发送到用户预留的手机号中,然后要求用户输入收到的验证码内容。
短信验证码的设计目的与上述三种验证码稍有不同,它不仅区分用户是人类还是计算机计算机,它还主要用于验证是否是用户本人操作。但是由于部分开发人员的安全意识不足,这类验证码也可能被轻易地攻破。
0x02 验证码识别原理与过程
验证码识别主要分成三部分:预处理,字符分割,字符识别。下面以静态图验证码(后面将简称为:图像验证码)为例来具体介绍识别原理。
预处理
预处理主要是将验证码图片进行色度空间转换、去除干扰、降噪、旋转等操作,为字符分割的时候提供一个质量较好的图片。
色度空间转换
在预处理是常用到色度空间转换,其中最主要的一种色度空间的转换就是二值化。二值化目的是将前景(主要为有效信息,即验证码信息)与背景(多为干扰信息)分离,尽最大程度讲有效信息提取出来,降低色彩空间维度,降低复杂度。
常用的方法:阈值法
统计一张图片(彩色图需转成256色灰度图)的灰度直方图后可以看到该图片在各灰度级上的像素分布数量。以下图的验证码为例,我们可以看到最左边(即纯黑色)与右侧其他灰度级像素的分布有明显一段隔开的区域,而图中纯黑色区域正好是有效信息(即验证码)。因此我们可以在该段隔开的区域里设一个阈值,像素值大于阈值的置为白色,小于像素值的置为黑色。

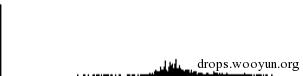

下图为通过上述办法二值化后的结果,背景已完全被去除,而有效信息被完整的保留了下来。

但是有时当前景与背景像素的灰度值交织在一起时,我们则很难通过阈值法提取出有效信息。以下面这张验证码为例,我们可以从其灰度直方图中看到所有像素点几乎都聚集在了一起。


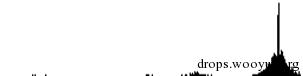

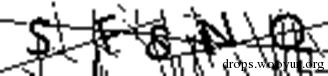
我们将阈值设在峰值左侧尝试二值化,可以从结果看出,这时有效信息非但没有被提取出来,反而带入了更强的干扰。对于此类验证码我们则需要在二值化之前先去除干扰。
代码如下:
#!python
def Binarized(Picture):
Pixels = Picture.load()
(Width, Height) = Picture.size
Threshold = 80 # 阈值
for i in xrange(Width):
for j in xrange(Height):
if Pixels[i, j] > Threshold: # 大于阈值的置为背景色,否则置为前景色(文字的颜色)
Pixels[i, j] = BACKCOLOR
else:
Pixels[i, j] = TEXTCOLOR
return Picture
去除干扰
上述实验已证明对于一些干扰较大的验证码我们需要先对其进行去干扰处理。去干扰的具体方法需要根据给定的验证码做有针对性的设计。 以某银行验证码为例,仔细观察可以发现验证码部分笔画宽度相对较宽,而干扰线宽度仅为1像素。针对此特性我设计了一种分离有效信息和干扰信息的算法。


具体算法过程如下:
将验证码转成256色灰度图像后,用一个33的窗口以此覆盖图像中的每一个像素点,然后将窗口中9个点的像素值进行排序后取中值Vmid,比较Vmid与33窗口中中心像素的值。如果二者差值大于预设的阈值,则判断该点颜色接近于白色还是黑色,若接近白色则将该点置为白色(255),若接近于黑色则置为黑色(0)。重复三次左右即可得到一个基本稳定的结果。


通过对比可以看出处理后的验证码区域灰度已被加深成黑色,与干扰线和背景的颜色已经明显区分开。从处理后的灰度直方图可以看出,像素点已主要集中在黑色(0)和白色(255)两个灰度级,这时在用阈值法二值化即可得到一个比较令人满意的结果了。

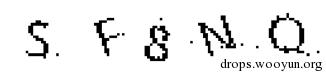
代码如下:
#!python
def Enhance(Picture):
'''分离有效信息和干扰信息'''
Pixels = Picture.load()
Result = Picture.copy()
ResultPixels = Result.load()
(Width, Height) = Picture.size
xx = [1, 0, -1, 0, 1, -1, 1, -1]
yy = [0, 1, 0, -1, -1, 1, 1, -1]
Threshold = 50
Window = []
for i in xrange(Width):
for j in xrange(Height):
Window = [i, j]
for k in xrange(8): # 取3*3窗口中像素值存在Window中
if 0 <= i + xx[k] < Width and 0 <= j + yy[k] < Height:
Window.append((i + xx[k], j + yy[k]))
Window.sort()
(x, y) = Window[len(Window) / 2]
if (abs(Pixels[x, y] - Pixels[i, j]) < Threshold): # 若差值小于阈值则进行“强化”
if Pixels[i, j] < 255 - Pixels[i,j]: # 若该点接近黑色则将其置为黑色(0),否则置为白色(255)
ResultPixels[i, j] = 0
else:
ResultPixels[i, j] = 255
else:
ResultPixels[i, j] = Pixels[i, j]
return Result
降噪
虽然上面结果的质量已经足以用于识别了,但我们仍然可以看到图中存在明显的噪声,我们还可以通过降噪将其质量进一步提高。
降噪的主要目的是去除图像中的噪声,降噪方法有方法有很多如:平滑、低通滤波等……这里介绍一种相对简单的方法——平滑降噪。具体方法是通过统计每个像素点周围像素值的个数来判断将改点置为和值。如果一个点周围白色点的个数大于某一阈值则将改点置为白色,反之亦然。通过平滑降噪已经可以将剩下的噪声点全部去除了。
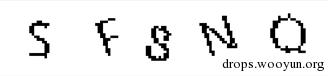
这里需要注意的是对二值图像进行降噪时应注意强度,当验证码笔画较细时,降噪强度过大可能会破坏验证码本身的信息,这可能会影响到后面的识别效果。
代码如下:
#!python
def Smooth(Picture):
'''平滑降噪'''
Pixels = Picture.load()
(Width, Height) = Picture.size
xx = [1, 0, -1, 0]
yy = [0, 1, 0, -1]
for i in xrange(Width):
for j in xrange(Height):
if Pixels[i, j] != BACKCOLOR:
Count = 0
for k in xrange(4):
try:
if Pixels[i + xx[k], j + yy[k]] == BACKCOLOR:
Count += 1
except IndexError: # 忽略访问越界的情况
pass
if Count > 3:
Pixels[i, j] = BACKCOLOR
return Picture
字符分割
得到经过预处理的图片后需要将每个字符单独分隔出来,这里简单介绍几种字符分隔的方法。
投影法
投影法是根据图片在投影方向上的像素个数进行分割的。
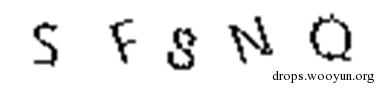

统计之前经过预处理图像在竖直方向上的像素个数可以看到每两个字符之间的像素个数有明显断开的情况。因此,我们在这些断开处进行分隔即可。
投影法对于处理字符在投影方向上分布比较开的情况有比较好的效果,但是如果遇到当两个字符在有影方向上有交集的情况则可能将两个字符误判成一个字符。
连通区域法
如果两个点相邻切颜色相同,则称这两个点是连通的。从一个点开始,所有与它直接或简介连通的点集即为一个连通区域。 连通区域法是从一个点开始找其连通区域,然后将每一个连通区域分割成一个块。

这样每个字符都将作为一个连通区域没分割出来。下图中每一种颜色是一个连通区域。
连通区域法可以很好解决两个字符虽然在有影方向上有交集可是没有粘连的情况,但是如果两个字符粘连在一起的话连通区域法也会将两个字符误判成一个。
对粘连字符的处理
如果对于上述情况我们可以通过最大字符宽度来判断连个字符是否发生粘连。我们可以先统计一些字符,记下最大字符宽度,当用连通区域法分隔出的字符宽度大于最大字符宽度时,我们则认为这是粘连字符。
这里介绍两种处理粘连字符的方法:
1. 根据平均字符宽度找极小值点分割字符
我们同样先统计一些字符,记下平均字符宽度,当遇到两个字符粘连时,从平均字符宽度处向两侧找竖直方向上有效像素个数的极小值点,然后从极小值点进行分割。

这种方法虽然在一定程度上可以解决粘连字符的问题,但是可能会破坏部分字符,这样可能对之后的识别造成干扰。
2. 滴水算法
未解决上述问题提出了滴水算法。滴水算法的过程是从图片顶部开始向下走,向水滴滴落一样沿着字符轮廓下滑,当滴到轮廓凹处渗入笔画,穿过笔画后继续滴落,最终水滴所经过的轨迹就构成了字符的分割路径。[ 2 ]

从上图可以看出粘连字符较好的被分割开并且在最大程度上保护了每一个字符的原貌。
代码如下:
#!python
def SplitCharacter(Block):
'''根据平均字符宽度找极小值点分割字符'''
Pixels = Block.load()
(Width, Height) = Block.size
MaxWidth = 20 # 最大字符宽度
MeanWidth = 14 # 平均字符宽度
if Width < MaxWidth: # 若小于最大字符宽度则认为是单个字符
return [Block]
Blocks = []
PixelCount = []
for i in xrange(Width): # 统计竖直方向像素个数
Count = 0
for j in xrange(Height):
if Pixels[i, j] == TEXTCOLOR:
Count += 1
PixelCount.append(Count)
for i in xrange(Width): # 从平均字符宽度处向两侧找极小值点,从极小值点处进行分割
if MeanWidth - i > 0:
if PixelCount[MeanWidth - i - 1] > PixelCount[MeanWidth - i] < PixelCount[MeanWidth - i + 1]:
Blocks.append(Block.crop((0, 0, MeanWidth - i + 1, Height)))
Blocks += SplitCharacter(Block.crop((MeanWidth - i + 1, 0, Width, Height)))
break
if MeanWidth + i < Width - 1:
if PixelCount[MeanWidth + i - 1] > PixelCount[MeanWidth + i] < PixelCount[MeanWidth + i + 1]:
Blocks.append(Block.crop((0, 0, MeanWidth + i + 1, Height)))
Blocks += SplitCharacter(Block.crop((MeanWidth + i + 1, 0, Width, Height)))
break
return Blocks
#!python
def SplitPicture(Picture):
'''用连通区域法初步分隔'''
Pixels = Picture.load()
(Width, Height) = Picture.size
xx = [0, 1, 0, -1, 1, 1, -1, -1]
yy = [1, 0, -1, 0, 1, -1, 1, -1]
Blocks = []
for i in xrange(Width):
for j in xrange(Height):
if Pixels[i, j] == BACKCOLOR:
continue
Pixels[i, j] = TEMPCOLOR
MaxX = 0
MaxY = 0
MinX = Width
MinY = Height
# BFS算法从找(i, j)点所在的连通区域
Points = [(i, j)]
for (x, y) in Points:
for k in xrange(8):
if 0 <= x + xx[k] < Width and 0 <= y + yy[k] < Height and Pixels[x + xx[k], y + yy[k]] == TEXTCOLOR:
MaxX = max(MaxX, x + xx[k])
MinX = min(MinX, x + xx[k])
MaxY = max(MaxY, y + yy[k])
MinY = min(MinY, y + yy[k])
Pixels[x + xx[k], y + yy[k]] = TEMPCOLOR
Points.append((x + xx[k], y + yy[k]))
TempBlock = Picture.crop((MinX, MinY, MaxX + 1, MaxY + 1))
TempPixels = TempBlock.load()
BlockWidth = MaxX - MinX + 1
BlockHeight = MaxY - MinY + 1
for y in xrange(BlockHeight):
for x in xrange(BlockWidth):
if TempPixels[x, y] != TEMPCOLOR:
TempPixels[x, y] = BACKCOLOR
else:
TempPixels[x, y] = TEXTCOLOR
Pixels[MinX + x, MinY + y] = BACKCOLOR
TempBlocks = SplitCharacter(TempBlock)
for TempBlock in TempBlocks:
Blocks.append(TempBlock)
return Blocks
字符识别
这里我将分隔出来的字符块与模板库中的字符信息进行比对,距离越小相似度越大。关于距离这里推荐使用编辑距离(Levenshtein Distance),他与汉明距离相比可以更好的抵抗字符因轻微的扭曲、旋转等变换而带来的误差。
为提高识别的精确度,我取了距离最小的前TopConut个字符信息来计算其中出现的每个字符与待识别字符的加权距离。我们令第i个字符的权重为TopConut - i,那么字符x与待识别字符的加权距离为:
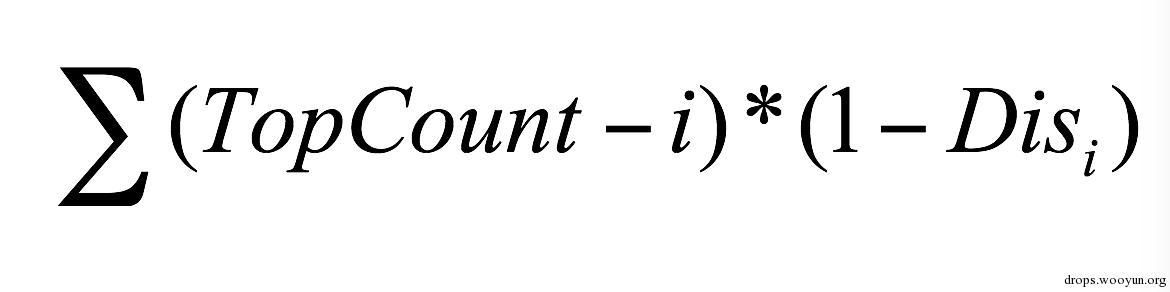
其中Disi是第i个字符信息与待识别字符的距离,i取前TopCount个字符信息中所有字符为x的下标。
0x03 最后
至此,一个验证码的识别已经全部完成了。
在整个验证码识别过程中有两个关键之处:一是有效信息的提取,只要提取出来较好质量的有效信息才能在识别时取得较高的识别率;二是字符的分割,现有的很多算法对单个字符的识别已经有较高的的识别率了,因此,如何较好的分隔字符也成为了验证码识别的关键。
知道了攻击的关键我们就可以有针对性的来改进我们的验证码了。对于设计验证码的一个基本原则就是利用人类识别与机器自动识别的差异来设计。这里我再给出几个我个人认为值得考虑的地方:
好的粘连可以有效的避免常见的字符分割算法;
让前景与背景具有相近的像素可以避免直接利用阈值法除去干扰信息;
在一定程度上要减少冗余,冗余越大,提供的信息越多,越容易被识别

厉害,内容很详细,对新手很有帮助。谢谢!
写得好!
好文章!如果不研究,看了真没用
很好,学习了
http://blog.csdn.net/xcy13638760/article/details/41445867
这文章也灰常不错,可惜木得源码啊~~呼呼~~
图像上的一些算法吧?
很叼,学习了~
现在图形验证码直接上svm,线性分类器,学习一阵子基本没问题,预处理还是那个套路,后面的识别跟cv沾点边的最终都逃不掉统计学的路啊。。
后台是怎么识别的呢
求完整源码。
太牛了
现在不是看到有有那种拼图验证码,滑动验证码么。
参考QQ验证码就行了
有没有比较好的设计算法。提供参考下!最近正头疼这事呢!
要增加破解难度,需要:
1.干扰线难以去除:干扰线颜色和字符颜色相同,宽度相似
2.字符无序扭曲
3.字符粘连
4.每个字符大小动态