最近在Kaggle上微软发起了一个恶意代码分类的比赛,并提供了超过500G的数据(解压后)。有意思的是,取得第一名的队伍三个人都不是搞安全出身的,所采用的方法与我们常见的方法存在很大不同,展现了机器学习在安全领域的巨大潜力。在仔细读完他们的代码和相关的论文后,我简单的进行了一些总结与大家分享。
需要指出的是,(1)比赛的主题是恶意代码的分类,不是病毒查杀(2)比赛采用的方法是纯静态分析的方法,不涉及行为分析等动态分析方法。
因此这不意味着这个方法能够取代现有的方法,但是了解它能够为安全研究人员提供一个崭新的思路,至于能否在工业界应用仍待进一步研究。
0x01 总览
背景
80年代末期,随着恶意代码的诞生,反恶意代码软件(或称反病毒软件)随之诞生。这个时期的恶意代码所采用的技术较为简单,这使得对应的检测技术也较为容易,早期的反病毒软件大都单一的采用特征匹配的方法,简单的利用特征串完成检测。随着恶意代码技术的发展,恶意代码开始在传播过程中进行变形以躲避查杀,此时同一个恶意代码的变种数量急剧提升,形态较本体也发生了较大的变化,反病毒软件已经很难提取出一段代码作为恶意代码的特征码。在这种情况下,广谱特征码随之诞生,广谱特征码将特征码进行了分段,通过掩码字节对需要进行比较的和不需要进行比较的区段进行划分。然而无论是特征码扫描还是广谱特征,都需要在获得恶意代码样本后,进行特征的提取,随后才能进行检测,这使得对恶意代码的查杀具有一定的滞后性,始终走在恶意代码的后面。为了针对变种病毒和未知病毒,启发式扫描应运而生,启发式扫描利用已有的经验和知识对未知的二进制代码进行检测,这种技术抓住了恶意代码具有普通二进制文件所不具有的恶意行为,例如非常规读写文件,终结自身,非常规切入零环等等。启发式扫描的重点和难点在于如何对恶意代码的恶意行为特征进行提取。特征码扫描、查找广谱特征、启发式扫描,这三种查杀方式均没有实际运行二进制文件,因此均可归为恶意代码静态检测的方法。随着反恶意代码技术的逐步发展,主动防御技术、云查杀技术已越来越多的被安全厂商使用,但恶意代码静态检测的方法仍是效率最高,被运用最广泛的恶意代码查杀技术。
数据格式
微软提供的数据包括训练集、测试集和训练集的标注。其中每个恶意代码样本(去除了PE头)包含两个文件,一个是十六进制表示的.bytes文件,另一个是利用IDA反汇编工具生成的.asm文件。如下图所示
方法简述
Kaggle比赛中最重要的环节就是特征工程,特征的好坏直接决定了比赛成绩。在这次Kaggle的比赛中冠军队伍选取了三个“黄金”特征:恶意代码图像、OpCode n-gram和Headers个数,其他一些特征包括ByteCode n-gram,指令频数等。机器学习部分采用了随机森林算法,并用到了xgboost和pypy加快训练速度。
本文主要关注恶意代码图像和OpCode n-gram,以及随机森林算法的应用。
0x02 恶意代码图像
这个概念最早是2011年由加利福尼亚大学的Nataraj和Karthikeyan在他们的论文 Malware Images: Visualization and Automatic Classification 中提出来的,思路非常新颖,把一个二进制文件以灰度图的形式展现出来,利用图像中的纹理特征对恶意代码进行聚类。此后,有许多研究人员在这个思路基础上进行了改进和探索。就目前发表的文章来看,恶意代码图像的形式并不固定,研究人员可根据实际情况进行调整和创新。
国内这方面的研究较少,去年在通信学报上有一篇《基于纹理指纹的恶意代码变种检测方法研究》,是由北京科技大学的韩晓光博士和北京启明星辰研究院等合作发表的,目测也是仅有的一篇。
本节介绍最简单的一种恶意代码图像绘制方法。对一个二进制文件,每个字节范围在00~FF之间,刚好对应灰度图0~255(0为黑色,255为白色)。将一个二进制文件转换为一个矩阵(矩阵元素对应文件中的每一个字节,矩阵的大小可根据实际情况进行调整),该矩阵又可以非常方便的转换为一张灰度图。
python代码如下
#!python
import numpy
from PIL import Image
import binascii
def getMatrixfrom_bin(filename,width):
with open(filename, 'rb') as f:
content = f.read()
hexst = binascii.hexlify(content) #将二进制文件转换为十六进制字符串
fh = numpy.array([int(hexst[i:i+2],16) for i in range(0, len(hexst), 2)]) #按字节分割
rn = len(fh)/width
fh = numpy.reshape(fh[:rn*width],(-1,width)) #根据设定的宽度生成矩阵
fh = numpy.uint8(fh)
return fh
filename = "your_bin_filename"
im = Image.fromarray(getMatrixfrom_bin(filename,512)) #转换为图像
im.save("your_img_filename.png")
利用该代码生成的几种病毒样本图像如下所示

用肉眼可看出,同一个家族的恶意代码图像在纹理上存在一定的相似性,不同的恶意代码家族是有一定区别的。如何用计算机发现和提取这些纹理的相似特征用以分类呢?这就需要用到计算机视觉里的一些技术了。在Nataraj和Karthikeyan的论文中采用的是GIST特征,GIST特征常用于场景分类任务(如城市、森林、公路和海滩等),用一个五维的感知维度来代表一个场景的主要内容(详情请参考文献[xx])。简单来说,输入图像,输出为对应的GIST描述符,如下图所示

在matlab实现里面每个图像的GIST描述符都用一个向量表示,最后用SVM完成分类训练。

这已经远远超出了场景识别所能做的。不过,国外有学者利用一些类似前文生成那种不规则图像来欺骗深度学习模型,如下图所示

详情请参考@王威廉老师的微博。当然,二者并没有什么直接关联,因为基于深度学习的图像识别系统的训练数据是一些有意义的图像。但这是一个非常有意思的巧合,至于基于深度学习的图像识别能否用于恶意代码图像的特征提取和分类,我认为是一个潜在的研究点,所能做的也不局限于此,如果有做深度学习的朋友可以伙同做安全的朋友一起研究交流。
0x03 OpCode n-gram
n-gram是自然语言处理领域的概念,早期的语音识别技术和统计语言模型与它密不可分。n-gram基于一个简单的假设,即认为一个词出现的概率仅与它之前的n-1个词有关,这个概率可从大量语料中统计得到。例如“吃”的后面出现“苹果”或“披萨”的概率就会比“公路”的概率大(正常的语料中基本不会出现“吃公路”这种组合),可以看出n-gram在一定程度上包含了部分语言特征。
将n-gram应用于恶意代码识别的想法最早由Tony等人在2004年的论文N-gram-based Detection of New Malicious Code 中提出,不过他们的方法是基于ByteCode的。2008年Moskovitch等人的论文Unknown Malcode Detection Using OPCODE Representation 中提出利用OpCode代替ByteCode更加科学。
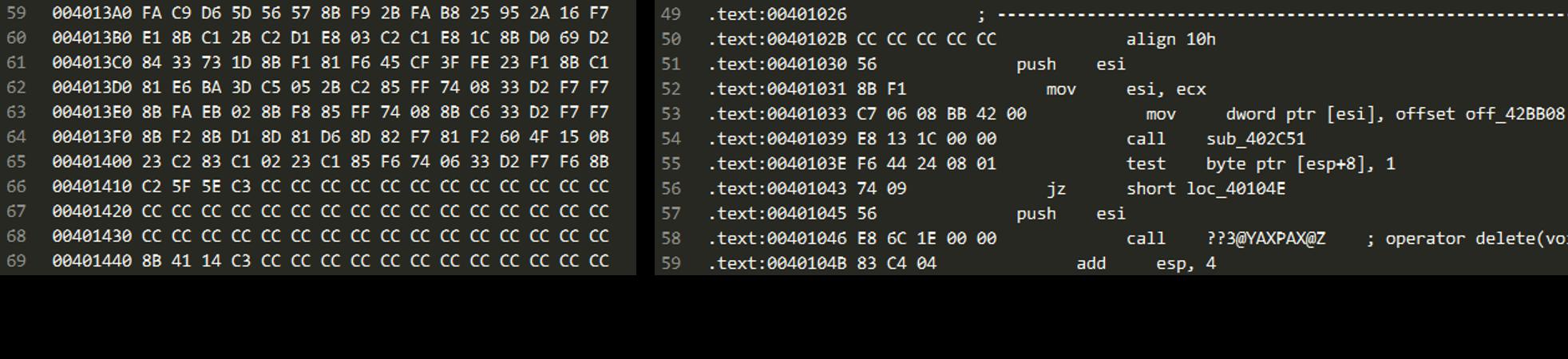
具体来说,一个二进制文件的OpCode n-gram如下图所示
针对这次Kaggle比赛提供的数据,用python提取出其n-gram特征
#!python
import re
from collections import *
# 从.asm文件获取Opcode序列
def getOpcodeSequence(filename):
opcode_seq = []
p = re.compile(r'\s([a-fA-F0-9]{2}\s)+\s*([a-z]+)')
with open(filename) as f:
for line in f:
if line.startswith(".text"):
m = re.findall(p,line)
if m:
opc = m[0][10]
if opc != "align":
opcode_seq.append(opc)
return opcode_seq
# 根据Opcode序列,统计对应的n-gram
def getOpcodeNgram(ops ,n = 3):
opngramlist = [tuple(ops[i:i+n]) for i in range(len(ops)-n)]
opngram = Counter(opngramlist)
return opngram
file = "train/0A32eTdBKayjCWhZqDOQ.asm"
ops = getOpcodeSequence(file)
opngram = getOpcodeNgram(ops)
print opngram
# output
# Counter({('mov', 'mov', 'mov'): 164, ('xor', 'test', 'setnle'): 155...
0x04 决策树和随机森林
决策树
决策树在我们日常生活中无处不在,在众多机器学习的书籍中提到的一个例子(银行预测客户是否有能力偿还贷款)如下图所示
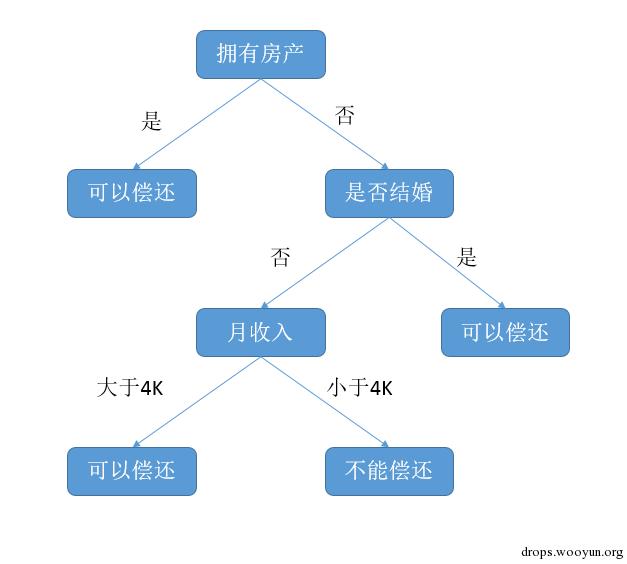
在这个在决策树中,非叶子结点如“拥有房产”、“是否结婚”就是所谓的特征,它们是依靠我们的知识人工提取出来的特征。但如果对某个领域不了解,特征数量又较多时,人工提取特征的方法就不可行了,需要依靠算法来寻找合适的特征构造决策树。
限于篇幅,决策树的构造等过程本文不进行展开,网上相关资源非常多。(只要能够充分理解熵和信息增益的概念,决策树其实非常简单)
随机森林
随机森林是一个非常强大的机器学习方法,顾名思义,它是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,预测这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
随机森林的思想与Adaboost里面的弱分类器组合成强分类器的思想类似,是一种“集体智慧”的体现。例如,屋子里面有n个人,每个人作出正确判断的概率为p(p略高于0.5,这时每个人可视为一个弱分类器),他们判断的过程独立互不影响,最终以多数人的判断为准。这里我们不从数学上来推导,类比抛硬币,对一枚均匀的硬币,抛n次的结果中,正面和反面的次数是差不多的。而对一枚不均匀的硬币,若出现正面的概率略大于反面,抛n次的结果中出现正面次数比反面次数多的概率就会很大。所以即使每个分类器的准确度不高,但是结合在一起时就可以变成一个强分类器。
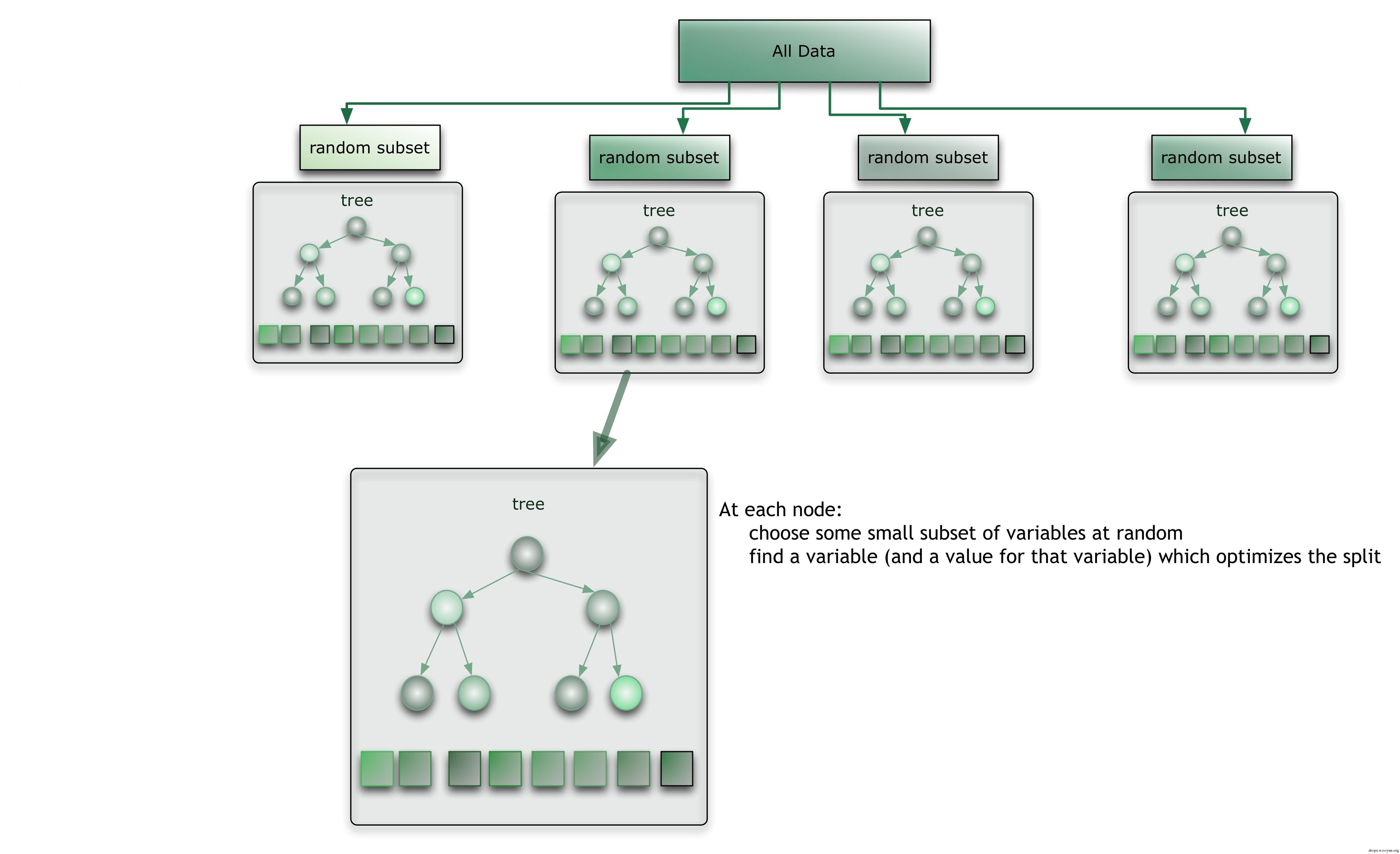
如图所示,将训练数据有放回的抽样出多个子集(即随机选择矩阵中的行),当然在特征选择上也可以进行随机化(即随机选择矩阵中的列,图中没有体现出来),分别在每个子集上生成对应的决策树
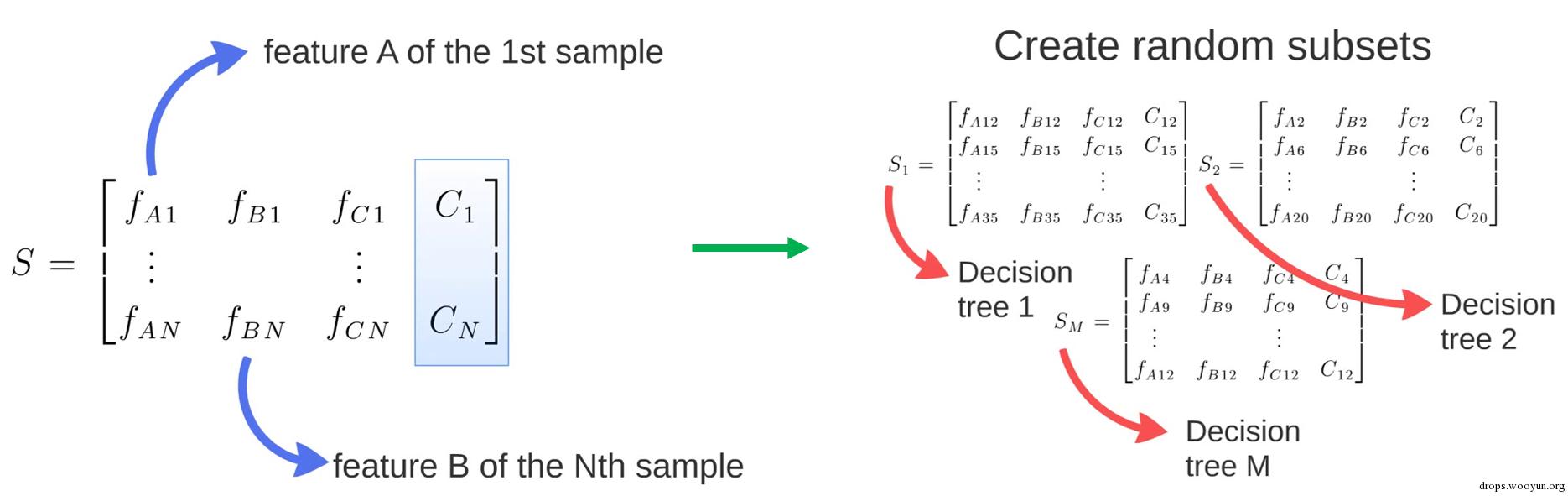
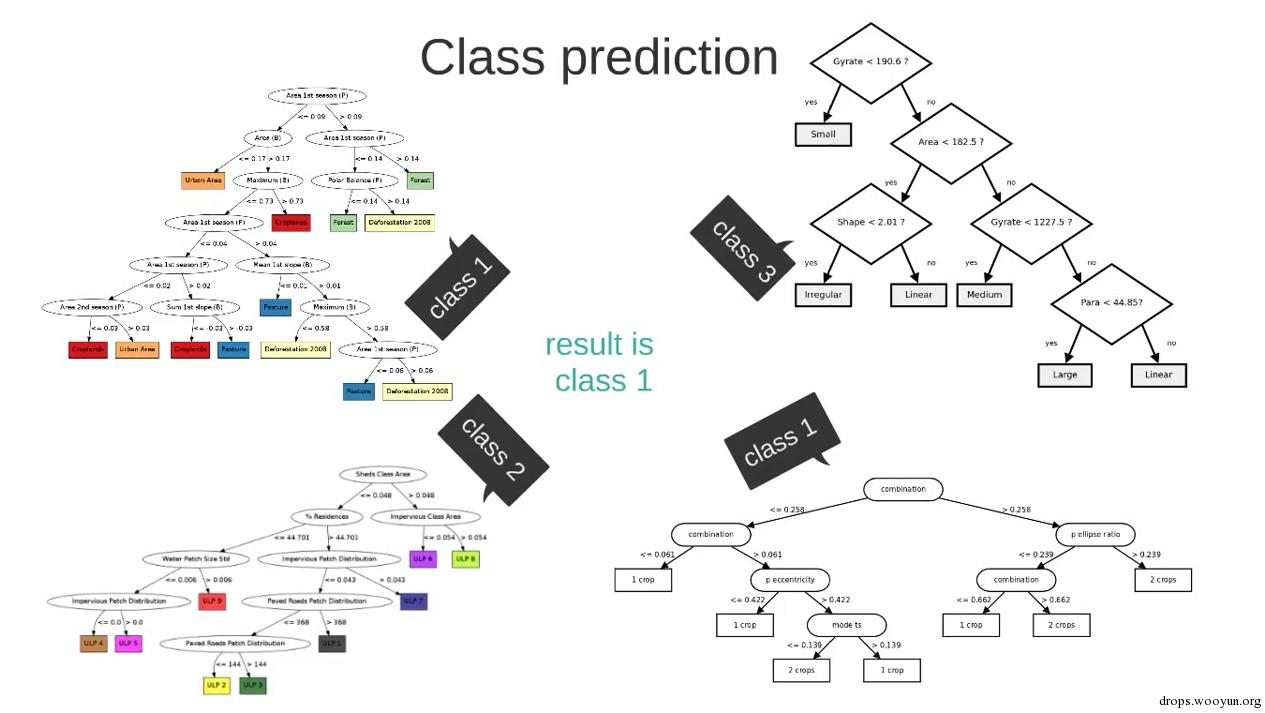
决策过程如下图所示(忽略画风不一致的问题...)
0x05 冠军队伍的实现细节
ASM文件图像
但是在Kaggle比赛中冠军队伍采用的方法并不是从二进制文件生成的图像,也不是从.bytes文件,竟然是从.asm文件生成的图像,他们也没有使用GIST特征,而是使用了前800个像素值作为特征,让人非常费解。
我专门给队伍里的Jiwei Liu同学发了一封邮件进行咨询,他给我的答复是:GIST特征与其他特征综合使用时影响整体效果,所以他们放弃了GIST特征,另外使用.asm文件生成图像纯属意外发现...
至于为什么是前800个像素,他的解释是通过反复交叉验证得出的,具体原因不清楚。(在后文的分析中我会谈谈我的一些看法)
OpCode n-gram
这部分的实现不复杂,他们选取n=4,在具体的特征选择上通过计算信息增益选取每个分类与其他分类区分度最高的750个特征。
其他特征
其他一些特征包括统计Headers,Bytecode n-gram(n=2,3,4),分析指令流(将每个循环固定展开5次)来统计指令频数,这些特征虽然不像前面提到的特征那么有效,但是确实可以在一定程度上提升最终成绩。
0x06 实验
冠军队伍的代码是为了参加比赛而写的,时间仓促,又是多人合作完成,导致组织结构很乱,且基本没有注释,可读性较差。更重要的是自己想动手实践一下,所以按照他们的思路写了几个简单的程序,忽略了一些处理起来比较复杂或者难以理解的过程,代码可以在我的github上下载
由于只是做一些简单的试验,不需要太多的数据(否则速度会非常慢),我从微软提供的训练数据中抽取了大概1/10左右的训练子集,其中从每个分类的中都随机抽取了100个样本(9个分类,每个样本2个文件,共1800个文件),这样也不需要用到pypy和xgboost,只需要用到numpy、pandas、PIL和scikit-learn这些库即可
友情提示:要进行这个实验,首先确保有一个比较大的硬盘,推荐使用Linux系统。
训练子集
这一步需要提前将完整训练集解压好,数量庞大,时间比较久。
#!python
import os
from random import *
import pandas as pd
import shutil
rs = Random()
# 读取微软提供的训练集标注
trainlabels = pd.read_csv('trainLabels.csv')
fids = []
opd = pd.DataFrame()
for clabel in range (1,10):
# 筛选特定分类
mids = trainlabels[trainlabels.Class == clabel]
mids = mids.reset_index(drop=True)
# 在该分类下随机抽取100个
rchoice = [rs.randint(0,len(mids)-1) for i in range(100)]
rids = [mids.loc[i].Id for i in rchoice]
fids.extend(rids)
opd = opd.append(mids.loc[rchoice])
opd = opd.reset_index(drop=True)
# 生成训练子集标注
opd.to_csv('subtrainLabels.csv', encoding='utf-8', index=False)
# 将训练子集拷贝出来(根据实际情况修改这个路径)
sbase = 'yourpath/train/'
tbase = 'yourpath/subtrain/'
for fid in fids:
fnames = ['{0}.asm'.format(fid),'{0}.bytes'.format(fid)]
for fname in fnames:
cspath = sbase + fname
ctpath = tbase + fname
shutil.copy(cspath,ctpath)
特征抽取
本实验中只用到了.asm文件,用到了.asm文件图像特征(前1500个像素)和OpCode n-gram特征(本实验取n=3,将总体出现频数大于500次的3-gram作为特征保留),实现代码与前文基本一致,具体细节可参考完整代码。
scikit-learn
因为scikit-learn的存在,将机器学习算法应用到其他领域变得非常方便快捷。例如我们已经抽取了这些恶意代码的OpCode n-gram特征("3gramfeature.csv"),利用scikit-learn即可快速训练一个随机森林
#!python
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn import cross_validation
from sklearn.metrics import confusion_matrix
import pandas as pd
subtrainLabel = pd.read_csv('subtrainLabels.csv')
subtrainfeature = pd.read_csv("3gramfeature.csv")
subtrain = pd.merge(subtrainLabel,subtrainfeature,on='Id')
labels = subtrain.Class
subtrain.drop(["Class","Id"], axis=1, inplace=True)
subtrain = subtrain.as_matrix()
# 将训练子集划分为训练集和测试集 其中测试集占40%
X_train, X_test, y_train, y_test = cross_validation.train_test_split(subtrain,labels,test_size=0.4)
# 构造随机森林 其中包含500棵决策树
srf = RF(n_estimators=500, n_jobs=-1)
srf.fit(X_train,y_train) # 训练
print srf.score(X_test,y_test) # 测试
实验结果
这里只对预测的准确度做一个简单的评判。
在只应用.asm文件图像特征(firstrandomforest.py)或者Opcode n-gram特征(secondrandomforest.py)的情况下,以及二者相结合的情况(combine.py),准确率如下所示
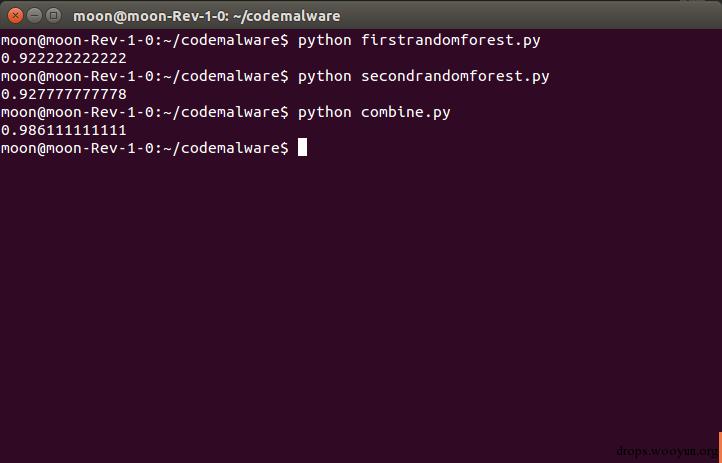
由于随机森林训练的过程中存在一定的随机性,因此每次结果不一定完全相同,但总的来说,二者结合的准确率通常要高出许多,基本可以达到98%以上的准确率,而且别忘了我们只用了不到1/10的数据
为什么是前800像素
观察.asm文件的格式,开头部分其实是IDA生成的一些信息,如下图所示
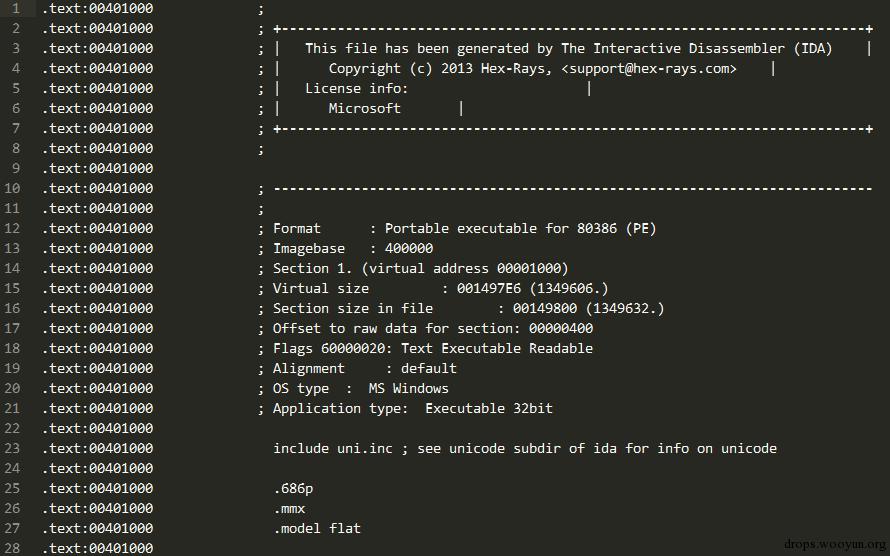
可以目测这个长度已经超出了800个像素(800个字节),实际上这800个像素和反汇编代码没有关系!完全就是IDA产生的一些信息,更进一步的说,实际上冠军队伍的方法压根与恶意代码图像没有关系,实际上是用到了IDA产生的信息。
但是仔细观察这些IDA信息,貌似长的都差不多,也没有什么有价值的信息,为什么可以有效区分恶意软件类型呢?
一个大胆的猜想是微软提前将这些恶意代码分好类,在调用IDA进行反汇编的时候是按照每个分类的顺序进行的,由于未知的原因可能导致了这些IDA信息在不同分类上有细微差别,恰好能作为一个非常有效的特征!
0x07 其他
- 好的方法总是简单又好理解的。这次Kaggle比赛也是如此,冠军队伍的方法没有特别难理解的部分。但是请注意:面上的方法并不能体现背后难度和工作量,真正复杂和耗时的部分在于特征选择和交叉验证上。比如他们最终放弃GIST特征正是经过反复对比验证才做出的决定。
- 这次的Kaggle比赛归根结底还是比赛,最终目标是取得最好成绩,不代表这个方法在实际中一定好用。
- 放弃GIST特征告诉我们一个宝贵的经验,并不是某个特征好就一定要用,还要考虑它和其他特征综合之后的效果。
- 比赛的数据是去除了PE头的,而输入输出表对分析恶意代码是很有帮助的,假如微软提供的数据包含了PE头,将输入输出表作为特征,最终的结果应该还能进一步提升。
- 这个方法的能够发现一些静态方法发现不了的变种,但对于未知的新品种依然无能为力(没有数据,机器学习巧妇难为无米之炊...)
- 可以尝试将该方法应用到Android和IOS平台的恶意代码检测中。
0x08 资源和参考资料
比赛说明和原始数据
https://www.kaggle.com/c/malware-classification/
冠军队伍相关资料
本文代码
https://github.com/bindog/ToyMalwareClassification
参考资料
Malware Images: Visualization and Automatic Classification
Detecting unknown malicious code by applying classification techniques on OpCode patterns(墙裂推荐)
如何使用GIST+LIBLINEAR分类器提取CIFAR-10 dataset数据集中图像特征,并用测试数据进行实验
How Random Forest algorithm works
Supervised Classification with k-fold Cross Validation on a Multi Family Malware Dataset
我的博客 <http://bindog.github.io/blog/ > 我的邮箱 bindog 艾特 奥特路克 .com 欢迎大家与我交流~
@bindog 不客气,楼主为了照顾大家七夕节情绪没有说冠军组有两个人是一对儿啊
@phunter 感谢大神的补充~
作为楼主的好友赶紧来支持一下!!
关于后面IDA 800像素部分一点评论就是,这是利用了这个比赛的data leakage。Kaggle的比赛一不小心就可能有data leakage(比如之前FB的一个stackoverflow文章加tag的比赛,测试数据和训练数据有很大一部分是完全重合的,导致最后发现这个秘密的人不用做任何机器学习都能拿好名次,FB那次丢大人了),后面用了这个可能的leakage得到好名次,这不算违规只能算是针对这个比赛的策略。但是这不能否定别的特征的重要性,也有很多别的组用了非IDA的特征做出比较好成绩,这说明机器的力量还是很强的,能辅助各位专家的日常工作。其他获胜队的解答报告都可以在 https://www.kaggle.com/c/malware-classification/forums 找到,里面丰富的知识啊。
顺便,这个比赛还出现一些比较萌的,有人在数据集里找到一些二进制代码,画出来是神奇的某两个公司的logo: https://www.kaggle.com/c/malware-classification/forums/t/12818/visualize-malware-patterns
用IDA的版本信息作为特征的分类结果,也能赢得“恶意代码分类”比赛的冠军,理论和应用还挺远。
[email protected]
现在是机器学习和安全,之后是深度学习和安全